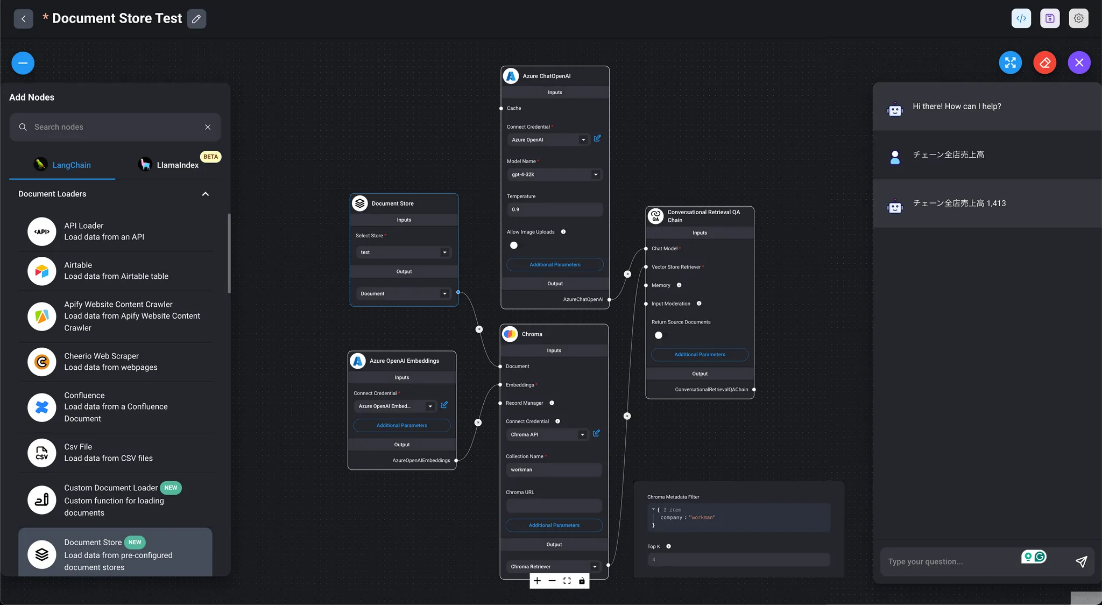
RAG
RAG
Utilización de RAG en DAIANA STUDIO
Para utilizar la generación aumentada por recuperación (RAG) en DAIANA STUDIO, es necesario utilizar los siguientes nodos de módulo:
- DocumentLoader: Carga documentos.
- Cargador de documentos
Carpeta con archivos
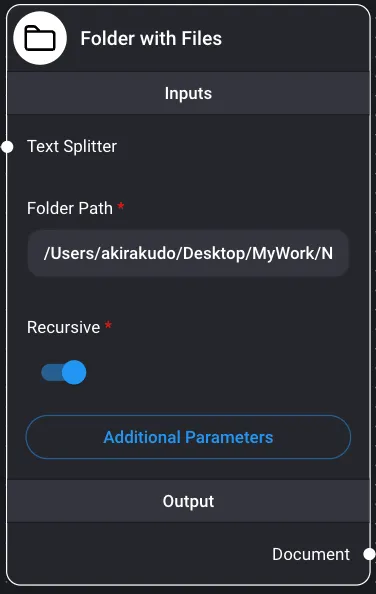
Permite explorar carpetas y recuperar datos de archivos. Lista de archivos cargables
| Extensión | Descripción |
|---|---|
| .json | Archivo JSON |
| .txt | Archivo de texto (TXT) |
| .csv | Archivo CSV (valores separados por comas) |
| .docx | Archivo de Microsoft Word |
| Archivo PDF | |
| .aspx | Página web generada con el framework Microsoft ASP.NET |
| .asp | Tecnología ASP (Active Server Pages) para generar páginas web dinámicas (también conocido como ASP Clásico o Legacy ASP) |
| .cpp | Archivo de código fuente en C++ |
| .c | Archivo de código fuente en C |
| .cs | Archivo de C# (CSharp) |
| .css | Archivo de hojas de estilo en cascada (CSS) |
| .go | Archivo de código fuente en Go |
| .h | Archivo de encabezado en C/C++ |
| .kt | Archivo de código fuente en Kotlin |
| .java | Archivo de código fuente en Java |
| .js | Archivo de JavaScript |
| .less | Archivo Less (preprocesador de CSS) |
| .ts | Archivo de TypeScript |
| .php | Archivo PHP |
| .proto | Archivo de definición de Protocol Buffers |
| .python | Archivo de código en Python |
| .py | Archivo de código en Python |
| .rst | Archivo reStructuredText |
| .ruby | Archivo de código en Ruby |
| .rb | Archivo de código en Ruby |
| .rs | Archivo de código en Rust |
| .scala | Archivo de código en Scala |
| .sc | Archivo de código en Scala |
| .scss | Archivo de estilo Sass |
| .sol | Archivo de código en Solidity |
| .sql | Archivo de código SQL |
| .swift | Archivo de código en Swift |
| .markdown | Archivo Markdown |
| .md | Archivo Markdown |
| .tex | Archivo LaTeX |
| .ltx | Archivo LaTeX |
| .html | Archivo HTML |
| .vb | Archivo de código en Visual Basic |
| .xml | Archivo XML |
Texto sin formato
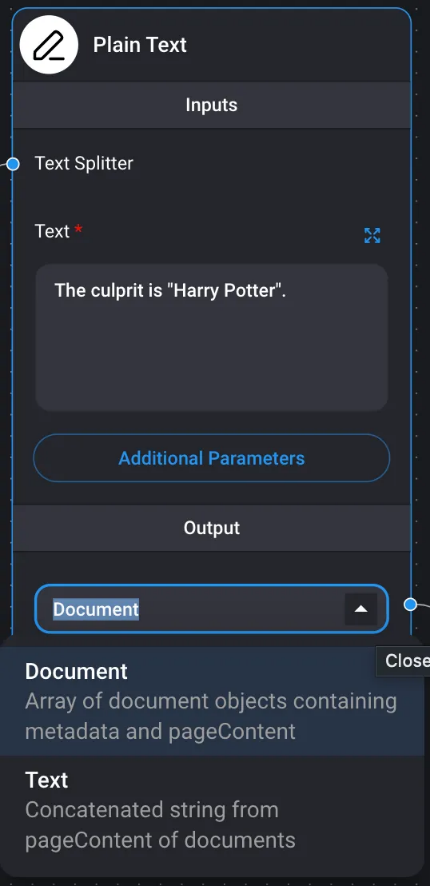
Permite recuperar datos de una cadena.
Entradas:
- Separadores de texto
- Separador de texto de caracteres
- Separador de texto HtmlToMarkdown
- Separador de texto Markdown
Prueba
- Los textos que se van a utilizar
Archivo de texto
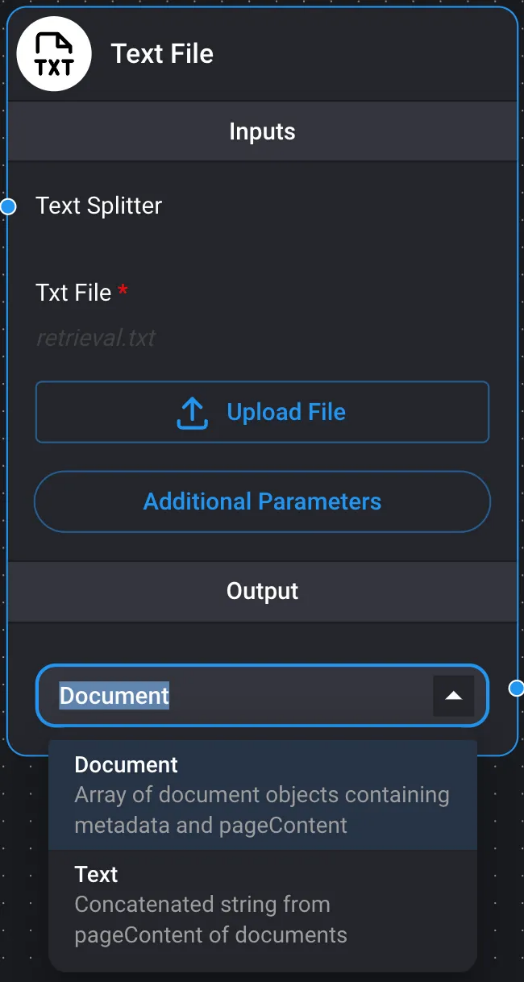
Permite recuperar datos de archivos de texto. Los formatos de archivo compatibles son:
| Extensión | Descripción |
|---|---|
| .txt | Archivo de texto (TXT) |
| .html | Archivo HTML |
| .aspx | Página web generada con el framework Microsoft ASP.NET |
| .asp | Archivo ASP (Active Server Pages) para páginas web dinámicas |
| .cpp | Archivo de código fuente en C++ |
| .c | Archivo de código fuente en C |
| .cs | Archivo de código fuente en C# (CSharp) |
| .css | Archivo de hojas de estilo en cascada (CSS) |
| .go | Archivo de código fuente en Go |
| .h | Archivo de encabezado en C/C++ |
| .java | Archivo de código fuente en Java |
| .js | Archivo de JavaScript |
| .less | Archivo Less (preprocesador de CSS) |
| .ts | Archivo de TypeScript |
| .php | Archivo PHP |
| .proto | Archivo de definición de Protocol Buffers |
| .python | Archivo de código en Python |
| .py | Archivo de código en Python |
| .rst | Archivo reStructuredText |
| .ruby | Archivo de código en Ruby |
| .rb | Archivo de código en Ruby |
| .rs | Archivo de código en Rust |
| .scala | Archivo de código en Scala |
| .sc | Archivo de código en Scala |
| .scss | Archivo de estilo Sass |
| .sol | Archivo de código en Solidity |
| .sql | Archivo de código SQL |
| .swift | Archivo de código en Swift |
| .markdown | Archivo Markdown |
| .md | Archivo Markdown |
| .tex | Archivo LaTeX |
| .ltx | Archivo LaTeX |
| .vb | Archivo de código en Visual Basic |
| .xml | Archivo XML |
Archivos PDF
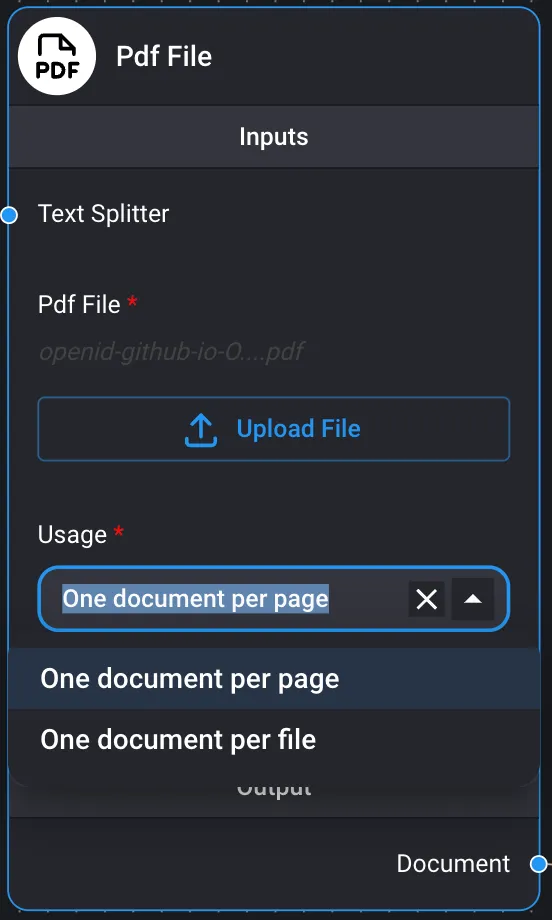
Es posible extraer datos de un archivo PDF.
Cheerio Web Scraper
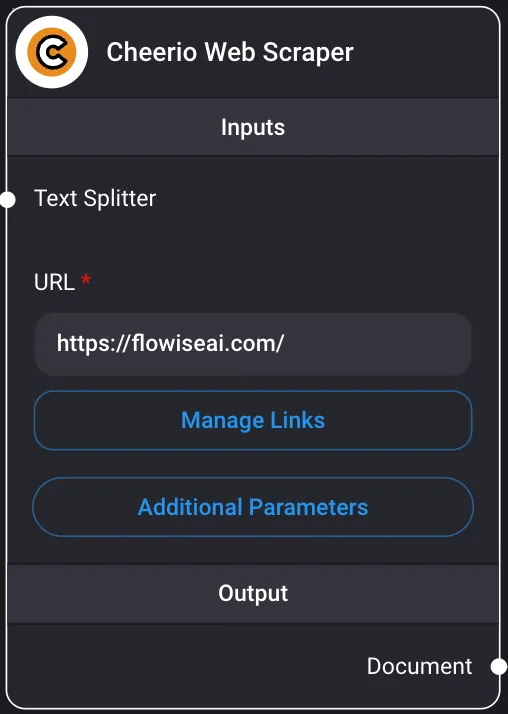
Permite recuperar datos de una página web.
- TextSplitter: divide los documentos cargados en fragmentos de texto más pequeños.
- Divisores de texto
- Divisor de texto por caracteres
- Divisor de texto HtmlToMarkdown
- Divisor de texto Markdown
- Incrustación: genera vectores de incrustación para fragmentos de texto.
- Incrustaciones
Incrustaciones de Ollama
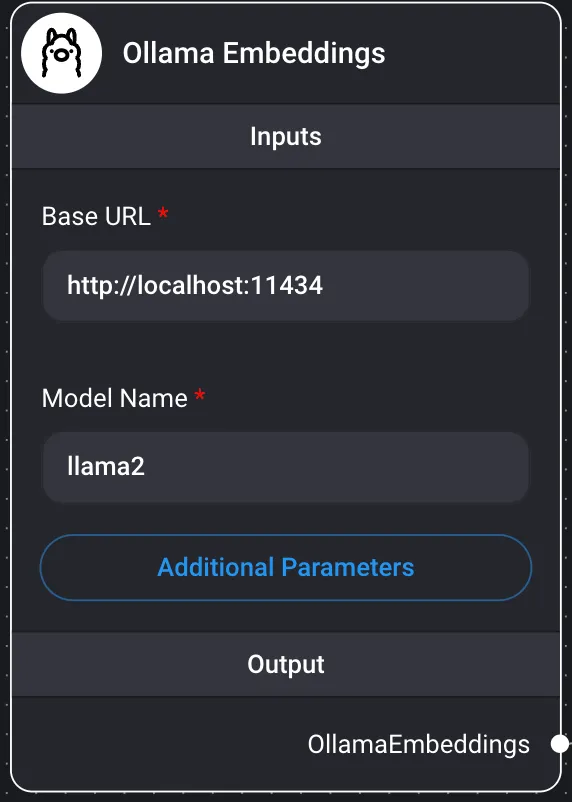
La incrustación es un vector de punto flotante (lista). La relación entre dos vectores se mide por la distancia entre ellos.
Una distancia menor indica una mayor similitud, mientras que una distancia mayor indica una menor similitud.
Mediante las incrustaciones, se pueden crear representaciones numéricas de datos de texto. Estas representaciones numéricas son útiles para buscar documentos similares. Utilice el modelo de código abierto de Ollama para generar incrustaciones para el texto especificado. Entradas
- URL base
- La URL del servidor LLM que se va a utilizar
- Nombre del modelo
- El nombre del modelo que se va a utilizar
Cómo confirmar
Parámetros adicionales
-
Número de GPU
- El número de capas que se enviarán a la GPU. En macOS, si se habilita la compatibilidad con Metal, el valor predeterminado es 1; si se deshabilita, es 0.
-
Número de subprocesos
- Es posible establecer el número de subprocesos que se utilizarán durante los cálculos. De forma predeterminada, Ollama detecta este valor para obtener un rendimiento óptimo. Se recomienda establecer este valor en el número de núcleos físicos de la CPU del sistema, no en los núcleos lógicos.
-
Usar MMap
- El uso de MMap permite operaciones de archivo más rápidas en comparación con las llamadas al sistema normales.
-
VectorStore:
- almacena y permite buscar los vectores de incrustación generados.
Chroma
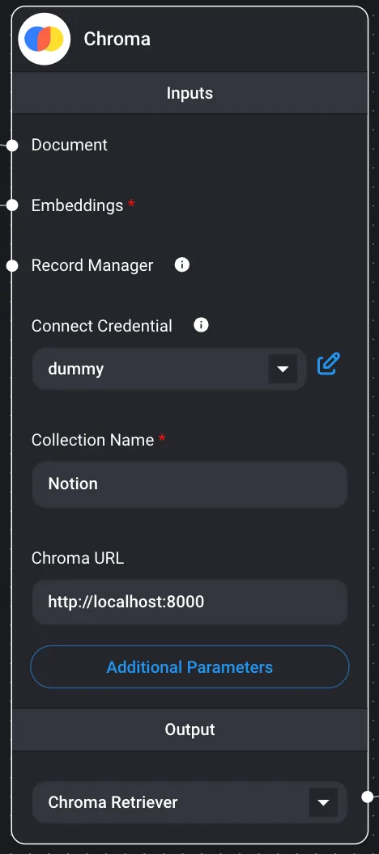
Chroma se utiliza como almacén de vectores, especializado en el almacenamiento y la recuperación de vectores numéricos de alta dimensión. Está diseñado para gestionar e indexar estos vectores de manera eficiente, lo que permite realizar búsquedas de similitud rápidas. Chroma permite realizar búsquedas de similitud durante las consultas y admite el filtrado de metadatos.
Redis
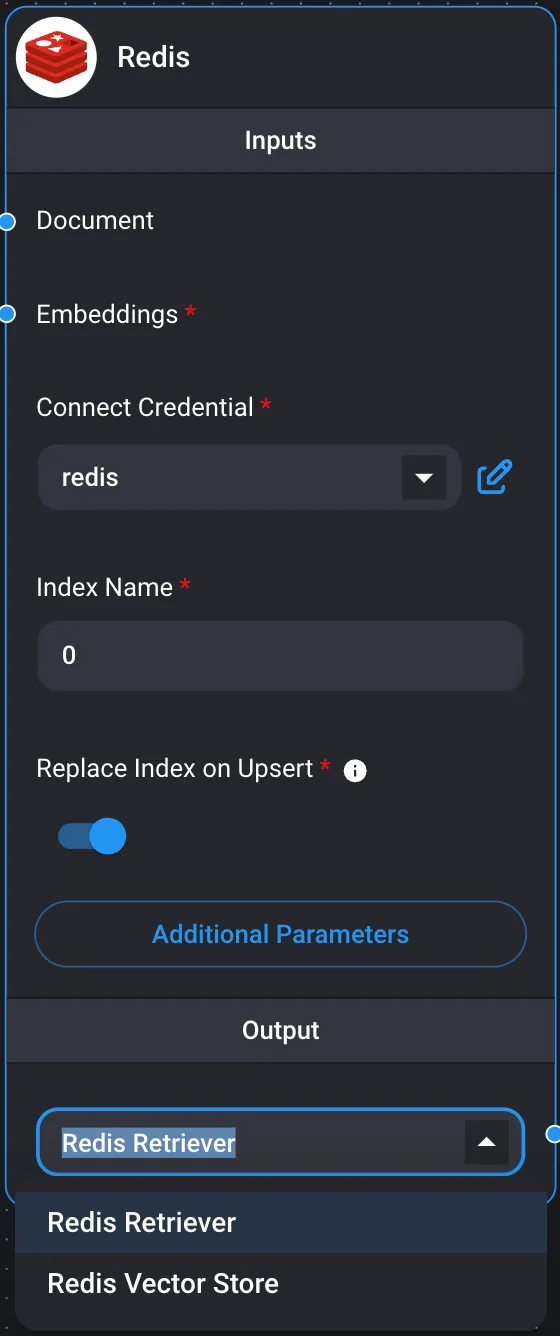
Un almacén vectorial o base de datos vectorial se refiere a un tipo de sistema de base de datos especializado en almacenar y recuperar vectores numéricos de alta dimensión. Los almacenes vectoriales están diseñados para gestionar e indexar estos vectores de manera eficiente, lo que permite realizar búsquedas de similitud rápidas.
El uso de Redis como almacén vectorial permite ejecutar búsquedas de similitud durante las consultas.
Almacén vectorial en memoria
La incrustación es un vector de punto flotante (lista). La relación entre dos vectores se mide por la distancia entre ellos. Una distancia menor indica una mayor similitud, mientras que una distancia mayor indica una menor similitud.
Mediante las incrustaciones, se pueden crear representaciones numéricas de datos de texto. Estas representaciones numéricas son útiles para buscar documentos similares.
Utilice el modelo de código abierto de Ollama para generar incrustaciones para el texto especificado.
Inputs
- URL base La URL del servidor LLM que se va a utilizar
- Nombre del modelo El nombre del modelo que se va a utilizar
Parámetros adicionales
-
Número de GPU
El número de capas que se enviarán a la GPU. En macOS, si se habilita la compatibilidad con Metal, el valor predeterminado es 1; si se deshabilita, es 0.
-
Número de subprocesos
Es posible establecer el número de subprocesos que se utilizarán durante los cálculos. De forma predeterminada, Ollama detecta este valor para obtener un rendimiento óptimo. Se recomienda establecer este valor en el número de núcleos físicos de la CPU del sistema, no en los núcleos lógicos.
-
Usar MMap
El uso de MMap permite operaciones de archivo más rápidas en comparación con las llamadas al sistema normales.
- Consulta: utiliza vectores de incrustación almacenados para buscar y recuperar documentos relevantes.
- Función Vector Store Retriever de QA Chain, etc.
- Asegúrese de que el recuento de tokens (longitud de caracteres) del prompt no supere el número máximo de tokens.
- Modelo de chat / Parámetros adicionales / Número máximo de tokens: 2048 (compruebe la cuota del modelo que está utilizando).

- Cadena de preguntas y respuestas de recuperación conversacional / Parámetros adicionales / Solicitud de reformulación

- Cadena de preguntas y respuestas de recuperación conversacional / Parámetros adicionales / Solicitud de reformulación
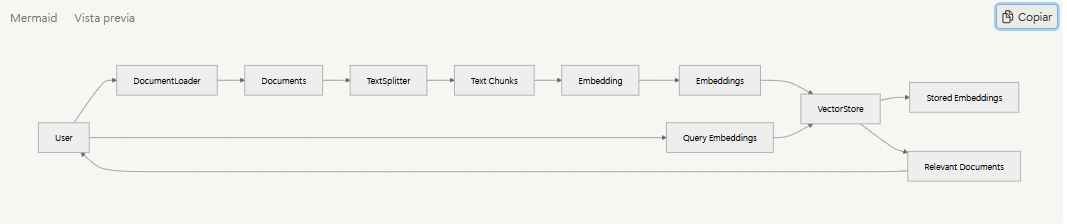
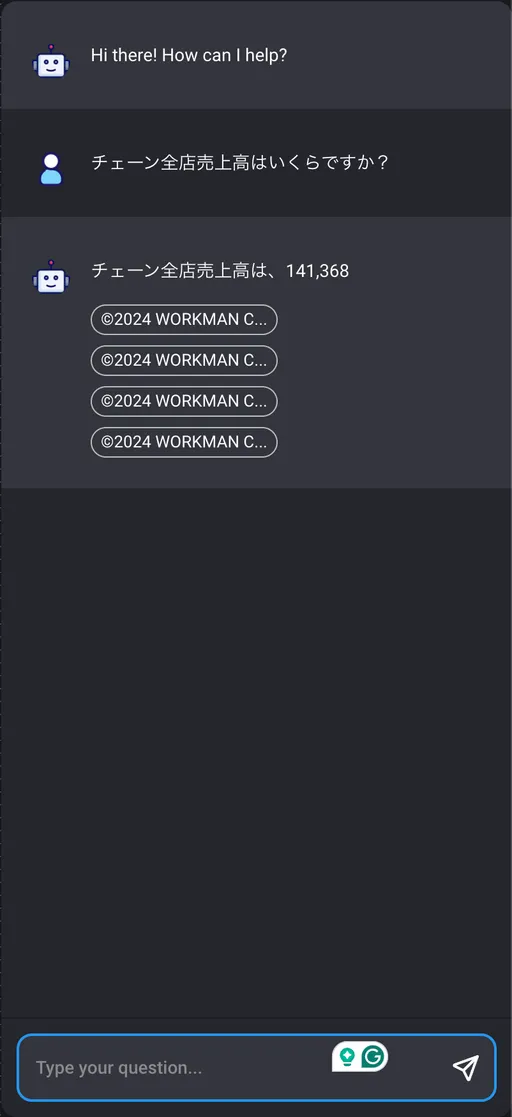
En el cuadro de chat, se recuperan los documentos relevantes para las consultas, y tanto la consulta como los resultados de la búsqueda se utilizan para consultar LLM, mostrándose los resultados en el cuadro de chat.
Para realizar esta búsqueda, los documentos deben vectorizarse y almacenarse en un almacén de vectores. Los documentos cargados por el cargador de documentos se convierten al formato chunk mediante el divisor de texto y, a continuación, se vectorizan mediante el proceso de incrustación.
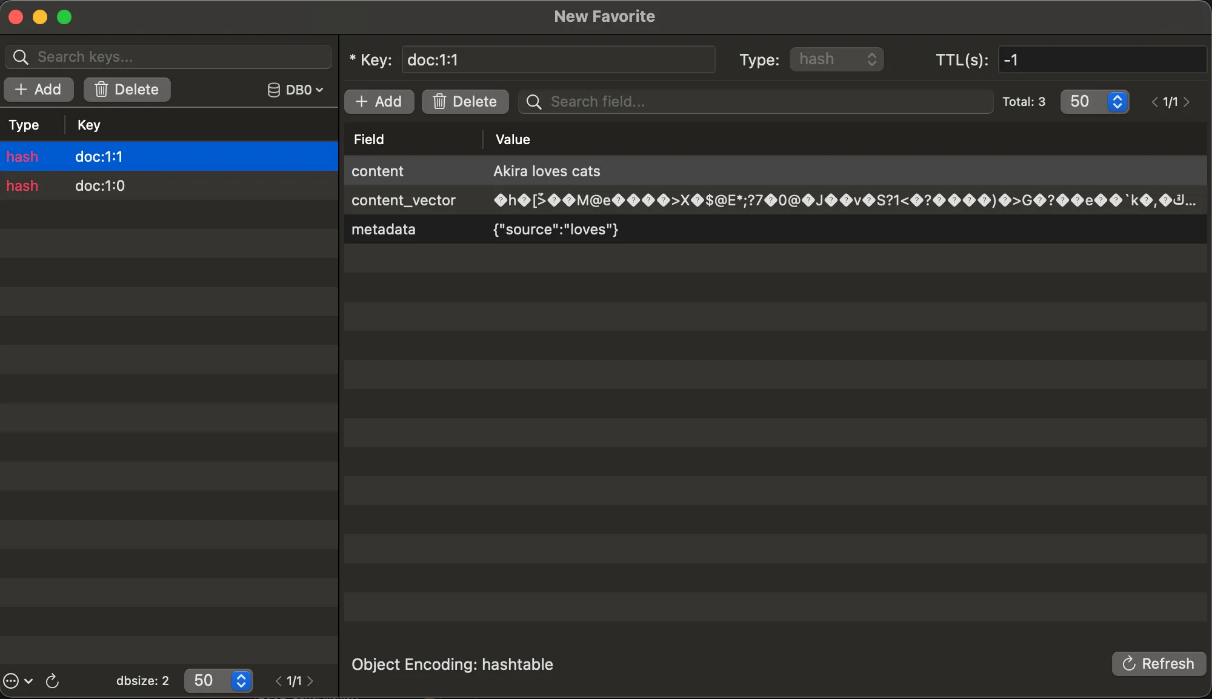
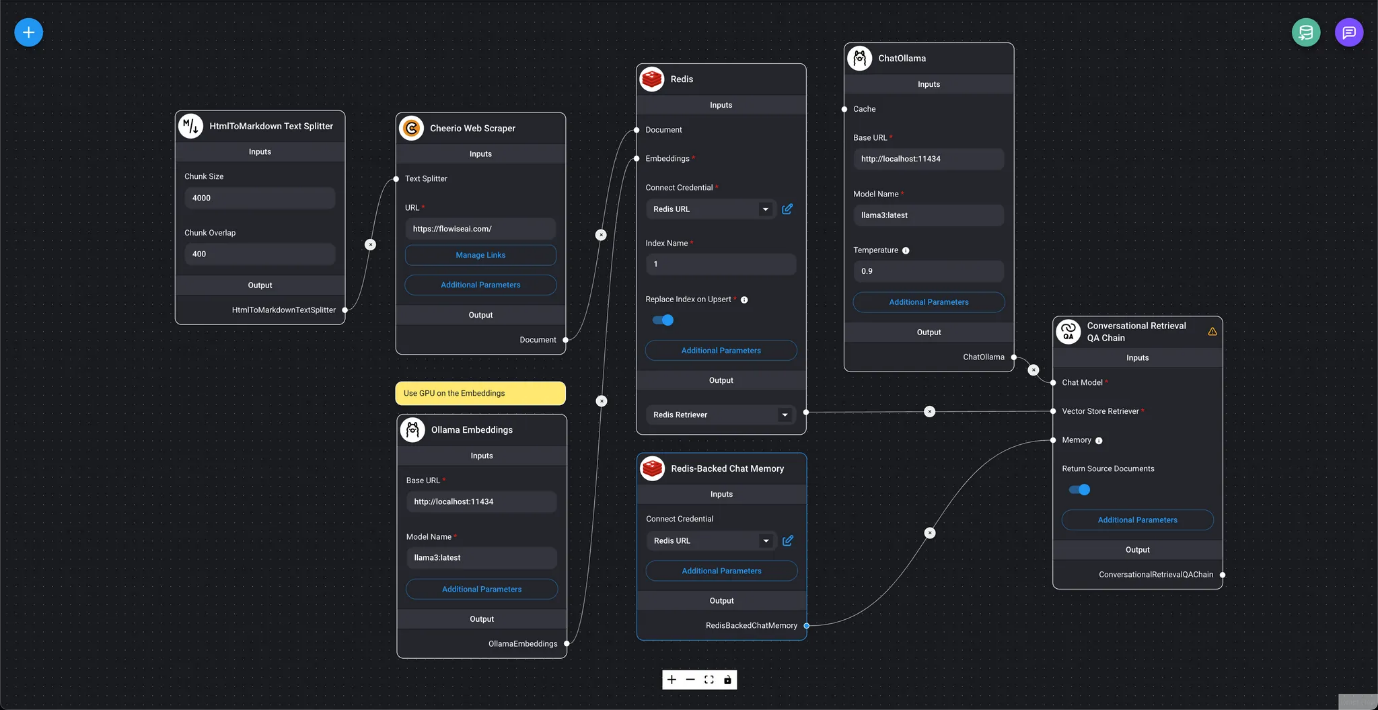
Uso de Redis como almacén de vectores
Uso de Redis como almacén vectorial. En la imagen siguiente, el nombre del índice se establece en 1 y la opción Upsert Index (Actualizar índice) está activada para el registro de datos. Esto permite actualizar los datos eliminando primero los datos registrados anteriormente antes de registrar los nuevos. Top K se establece en el valor predeterminado de 4, lo que limita los resultados de la búsqueda a un máximo de 4 elementos.
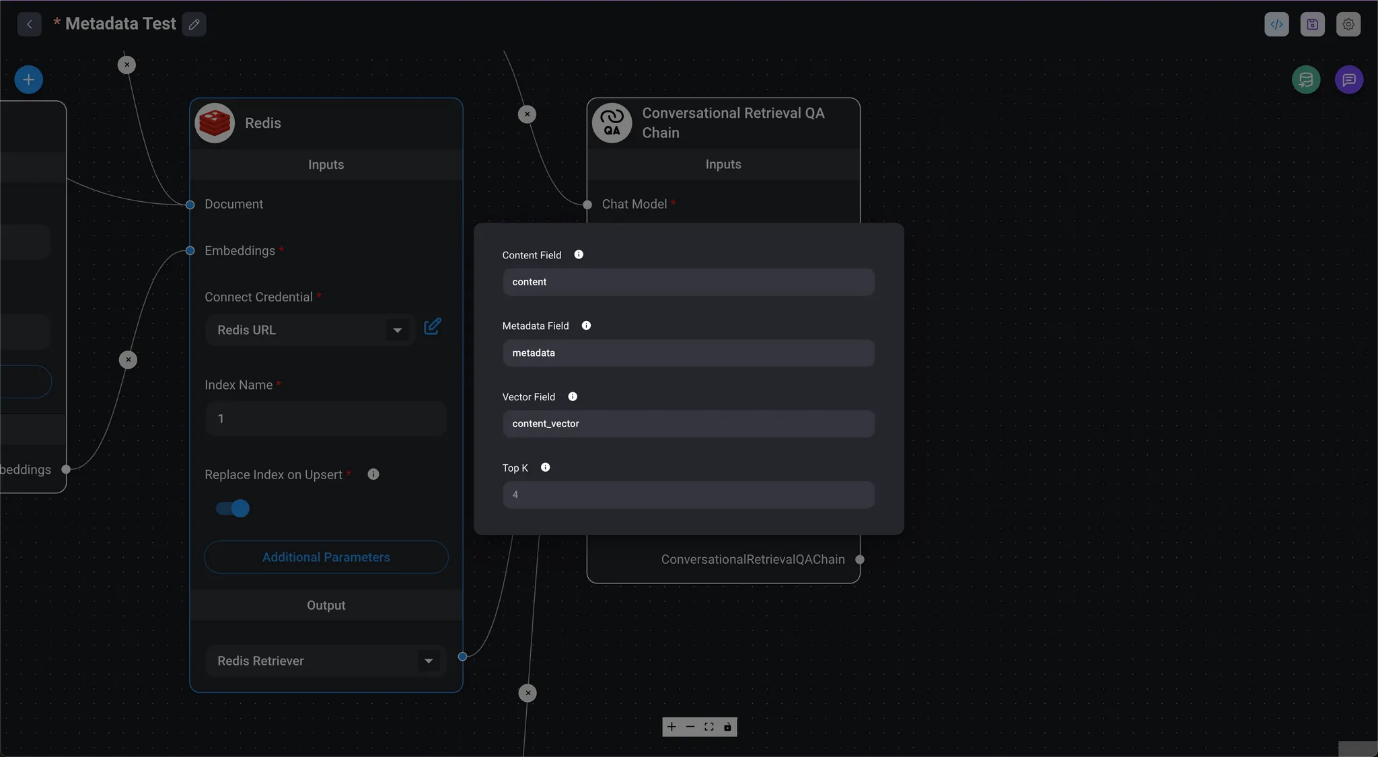
- Haga clic en el botón «Upsert» en el cuadro de diálogo «Almacenamiento vectorial Upsert» al que se accede desde el botón «Base de datos vectorial Upsert».
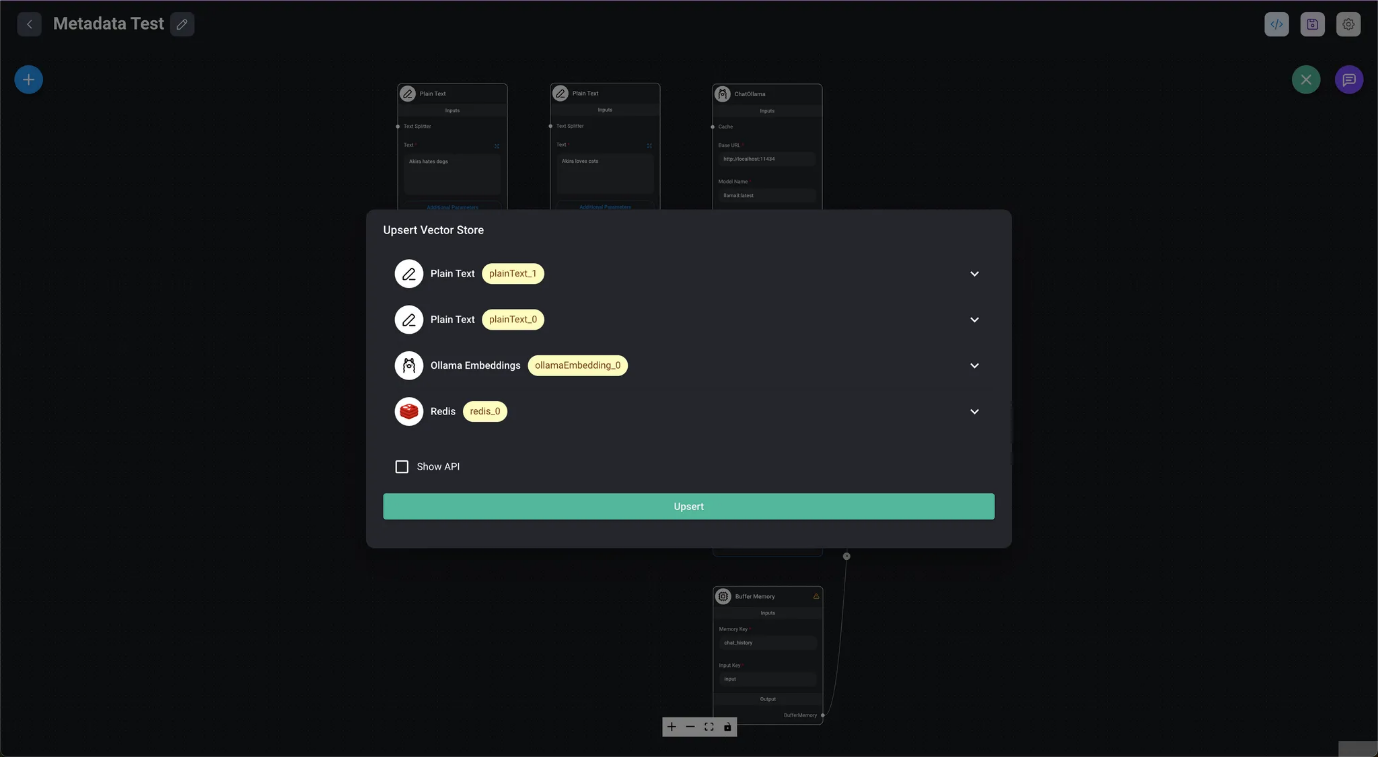
Si se realiza correctamente, se mostrarán el recuento de registros registrados y el estado.
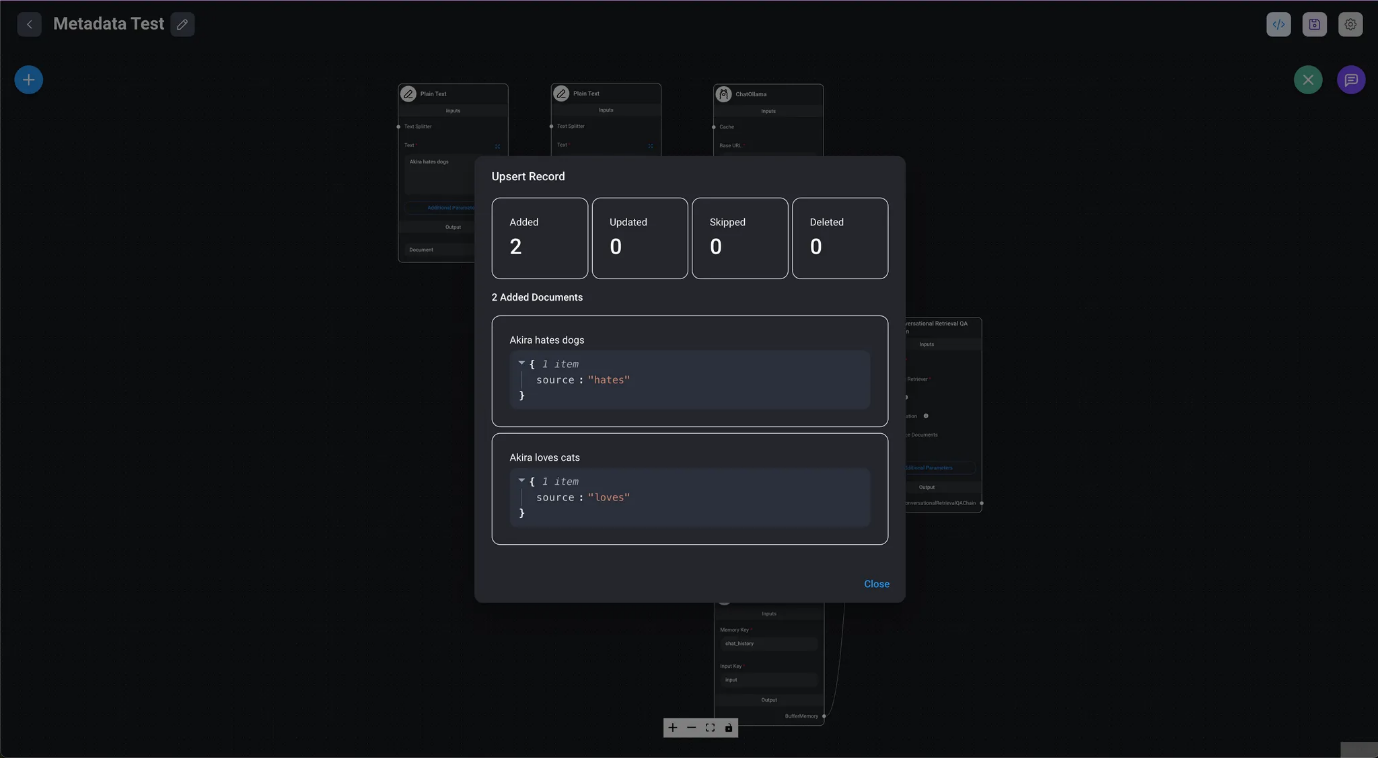
- Compruebe los registros en el índice Redis.
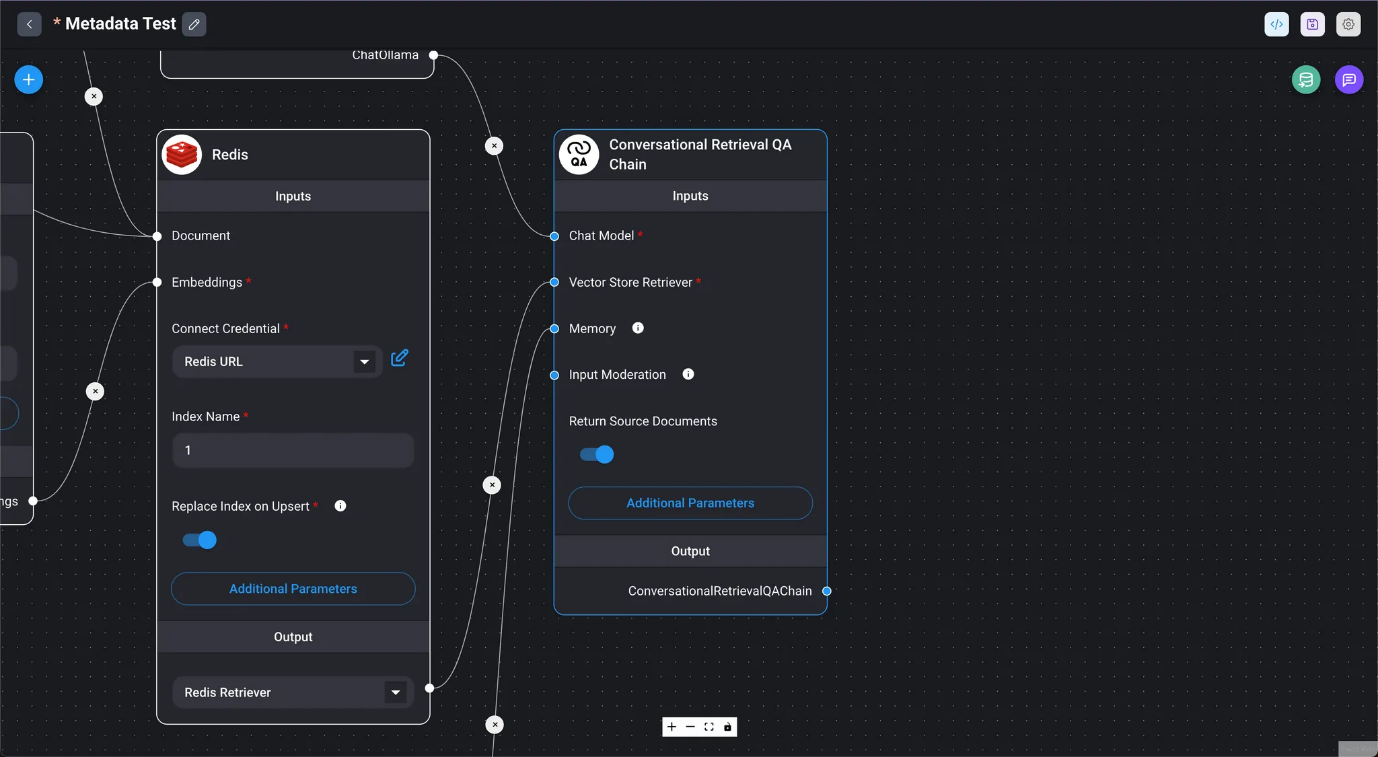
- Cuando «Devolver documentos de origen» está activado en Chain, los documentos utilizados en la consulta LLM se mostrarán debajo de la respuesta como botones de URL de archivo.
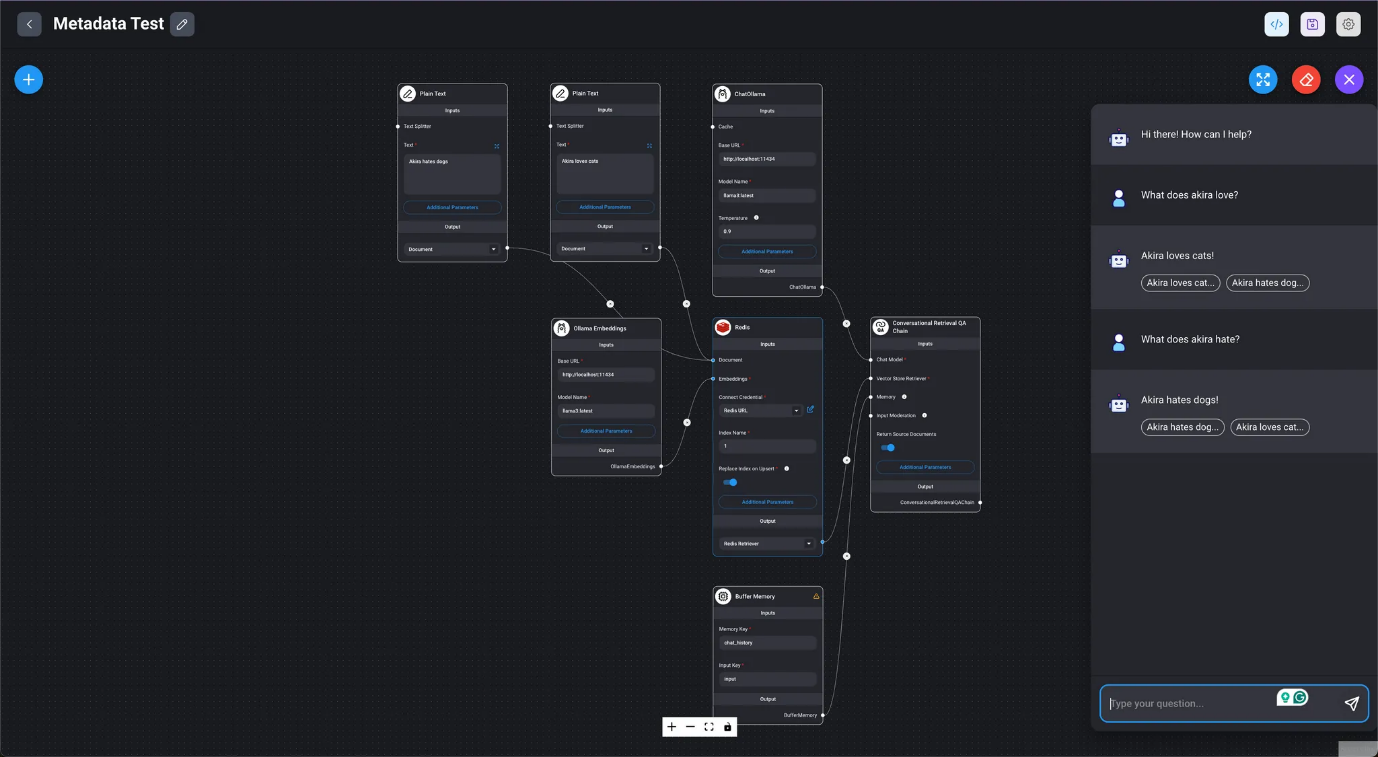
Uso del filtrado de metadatos con Chroma
Para utilizar el filtrado de metadatos, es necesario utilizar una base de datos compatible. En este caso, utilizamos Chroma para este fin.
- Configure el filtro de metadatos de Chroma desde el botón Parámetros adicionales en Chroma. Asegúrese de marcar previamente la casilla Metadatos en el cargador de documentos dentro de Chatflow.
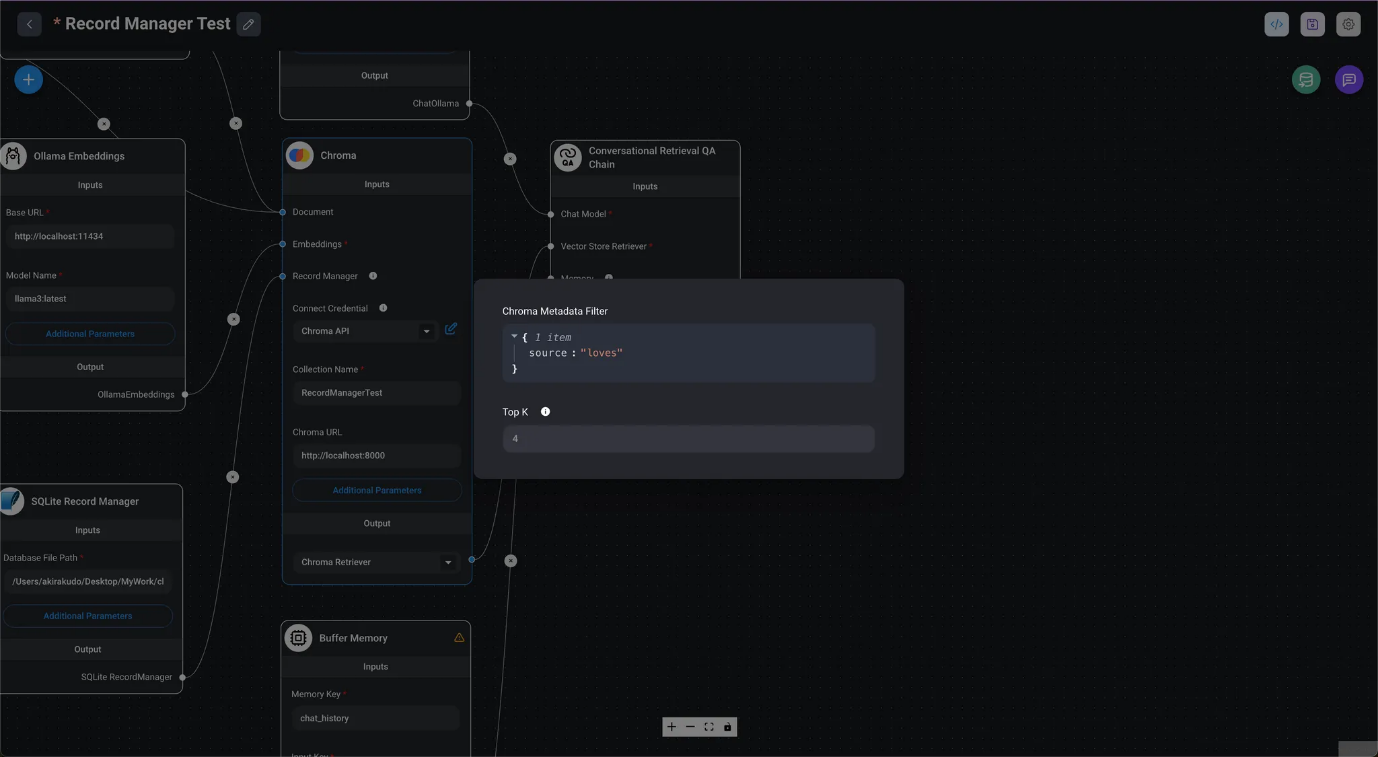
- Aquí, las consultas LLM se realizan utilizando documentos obtenidos mediante el filtrado con «loves».
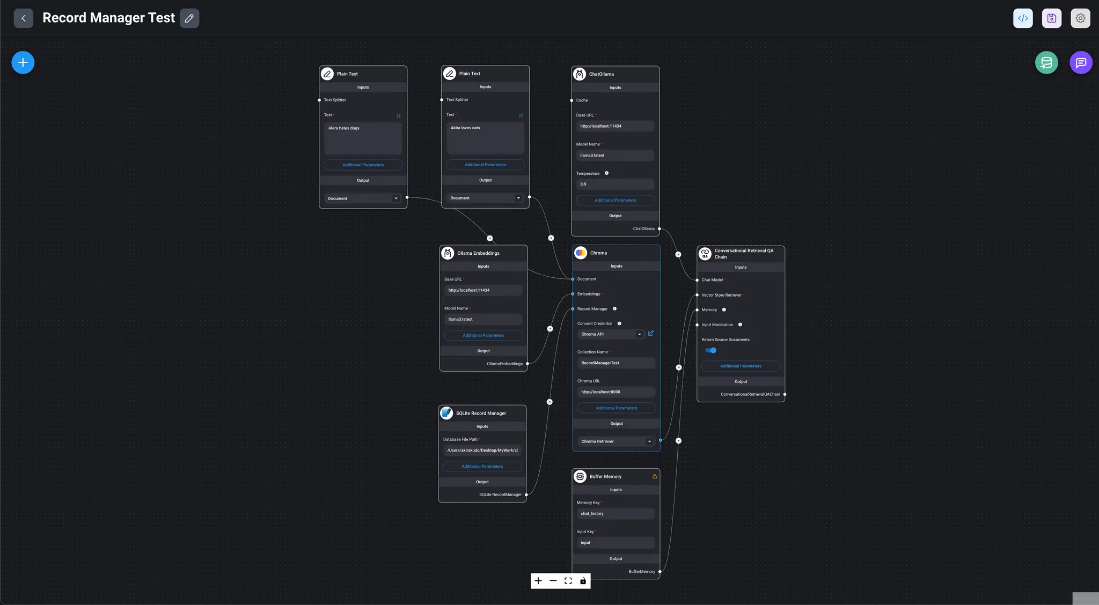
Uso de Record Manager con SQLite
Configure la ruta del archivo de base de datos con el nombre completo del archivo como ruta completa y configure Limpieza en Completa en Parámetros adicionales para lograr el mismo efecto que Upsert.
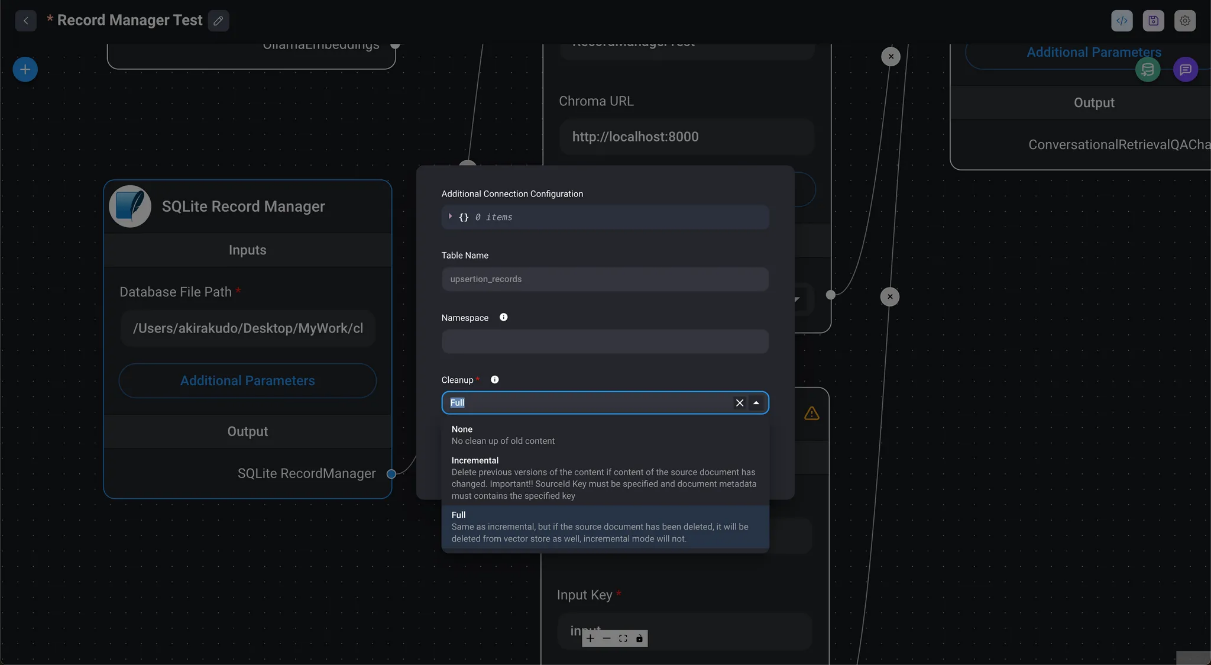
Ejemplo: /var/tmp/RecordManager.sqlite3
Uso de PDF como documento
El uso de Document Loader / PDF File permite extraer texto de archivos PDF. Lamentablemente, no es posible extraer archivos de imagen de archivos PDF.
Al convertir una página web a un archivo PDF, utilice servicios o herramientas como:
Uso de páginas web como documentos
El uso de Document Loader / Cherrio Web Scraper le permite cargar páginas web. También puede extraer enlaces utilizando el método Get Relative Links.
Gestión de RAG con el almacén de documentos
El uso de un almacén de documentos permite gestionar los documentos en función de fines específicos.
- Crear un nuevo almacén de documentos Cree un nuevo almacén de documentos haciendo clic en el botón «Añadir nuevo». Introduzca el nombre y la descripción y, a continuación, haga clic en el botón «Añadir».
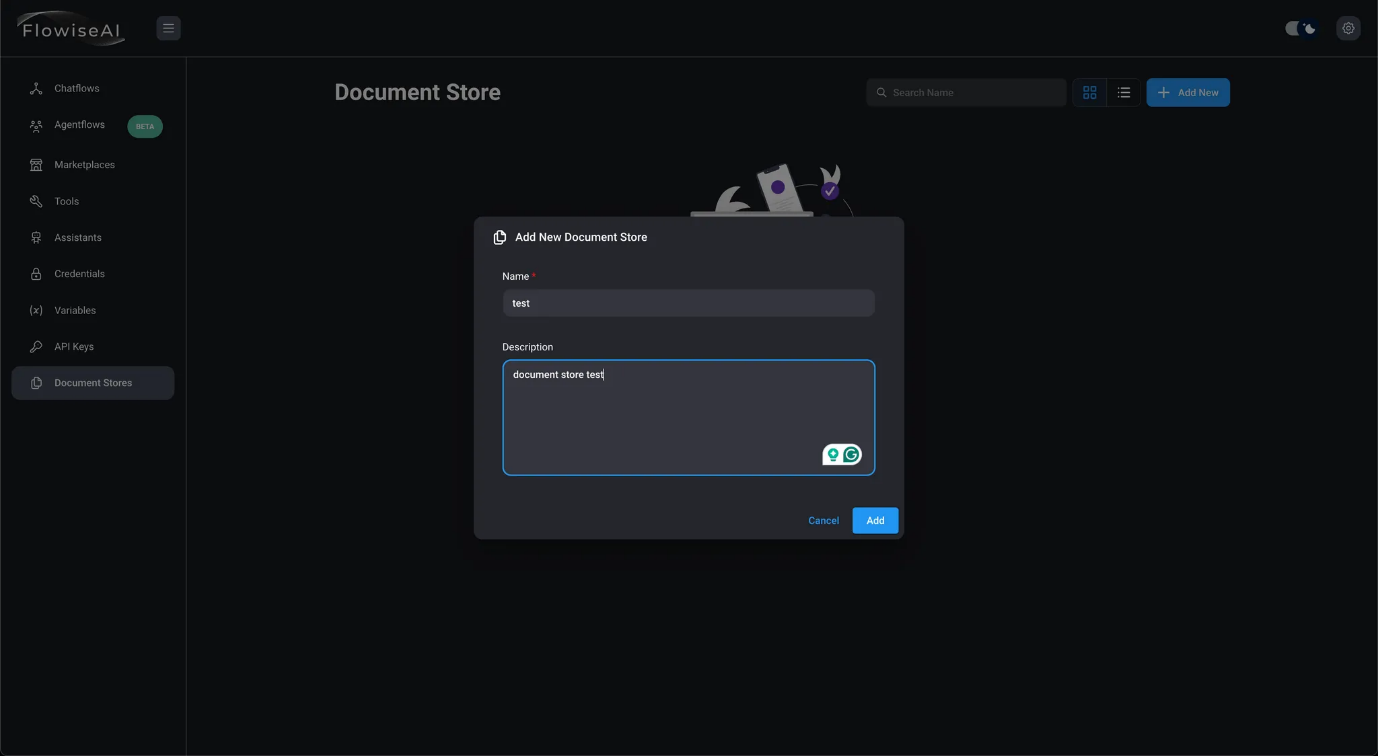
- Después de hacer clic en el botón «Añadir», se le redirigirá a la página principal de los almacenes de documentos.
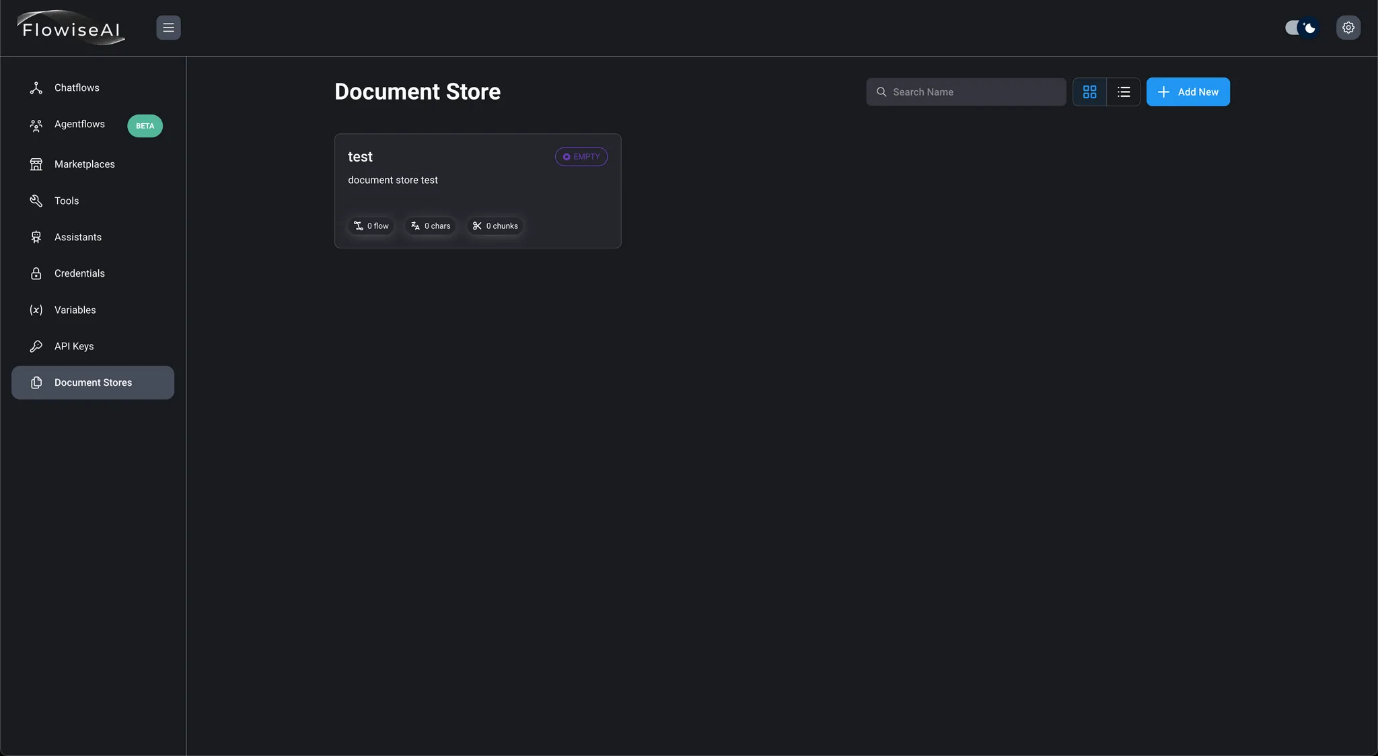
- Editar un almacén de documentos existente Al hacer clic en el almacén de documentos, se mostrará la pantalla de edición.
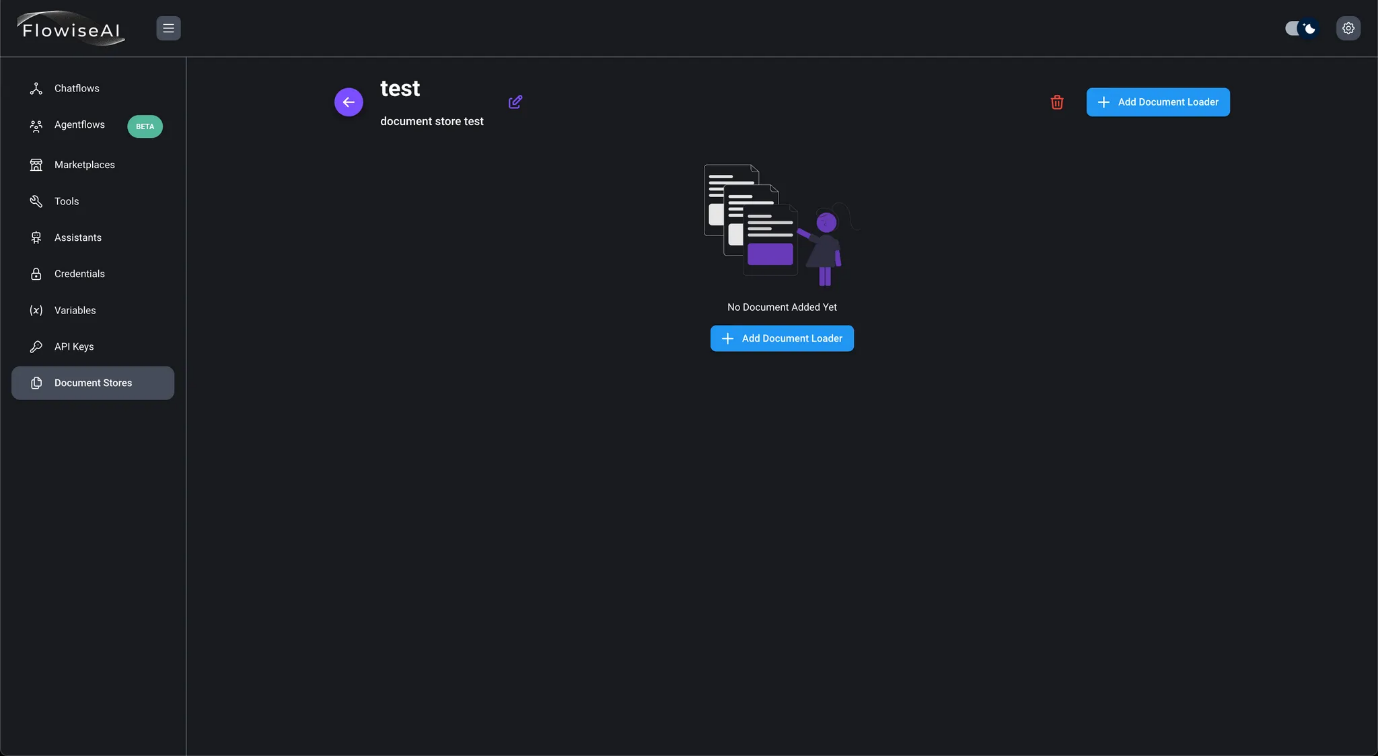
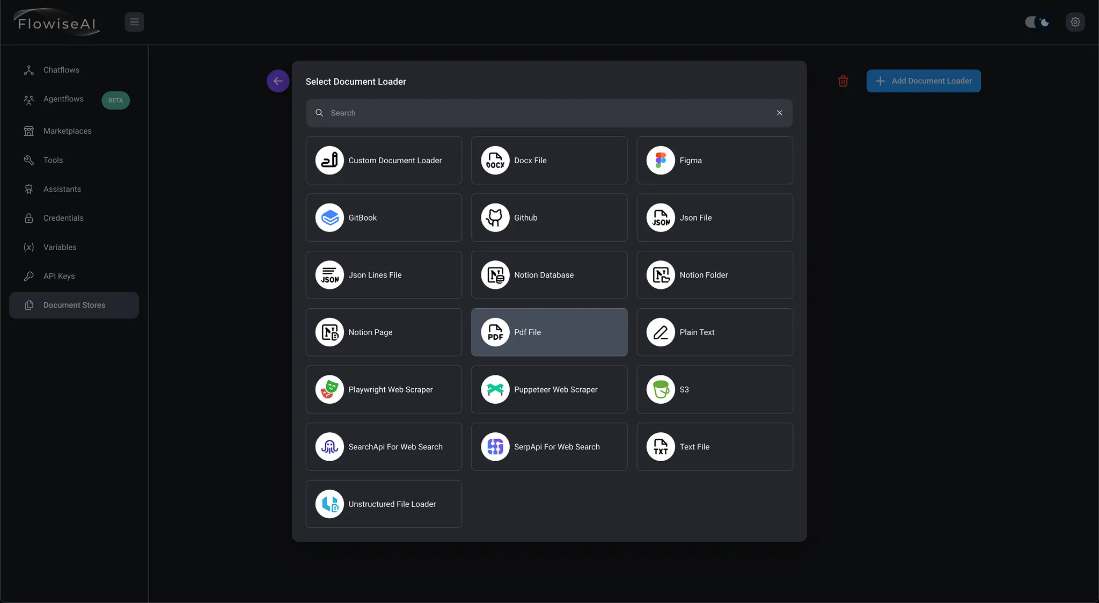
- Haga clic en el botón «Añadir cargador de documentos» para añadir un cargador de documentos. Aquí, seleccione «Archivo PDF» como ejemplo.
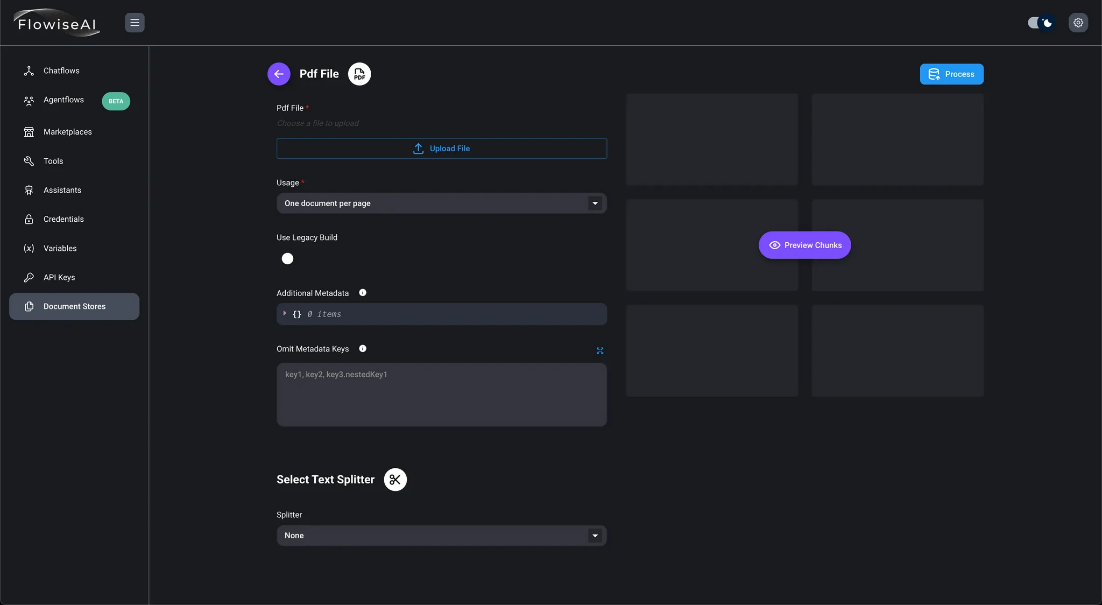
- Cuando suba un archivo utilizando «Subir archivo», se mostrará el nombre de archivo especificado.
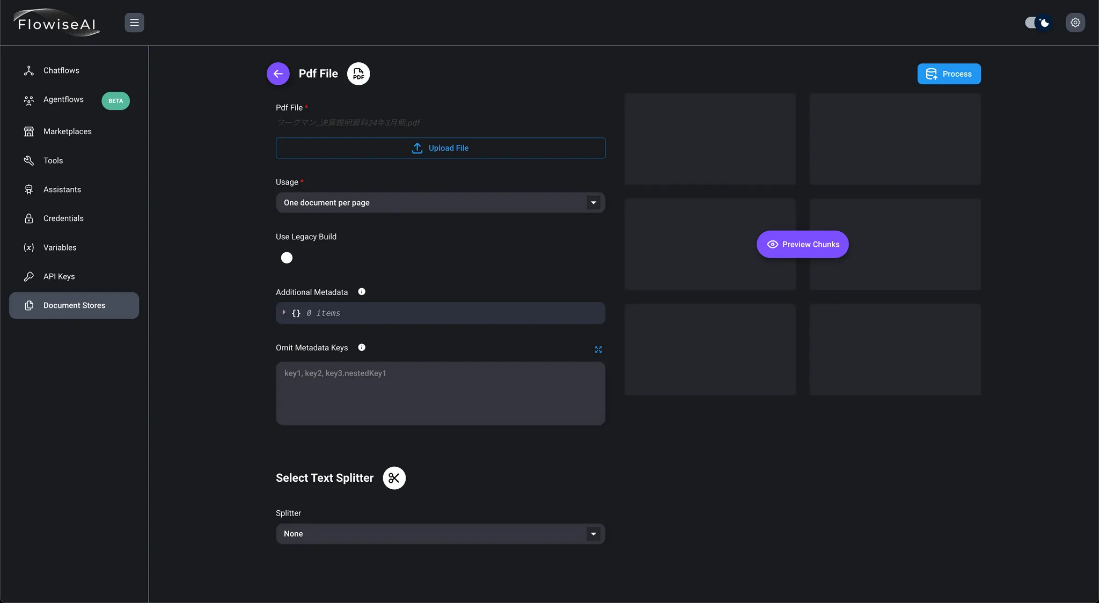
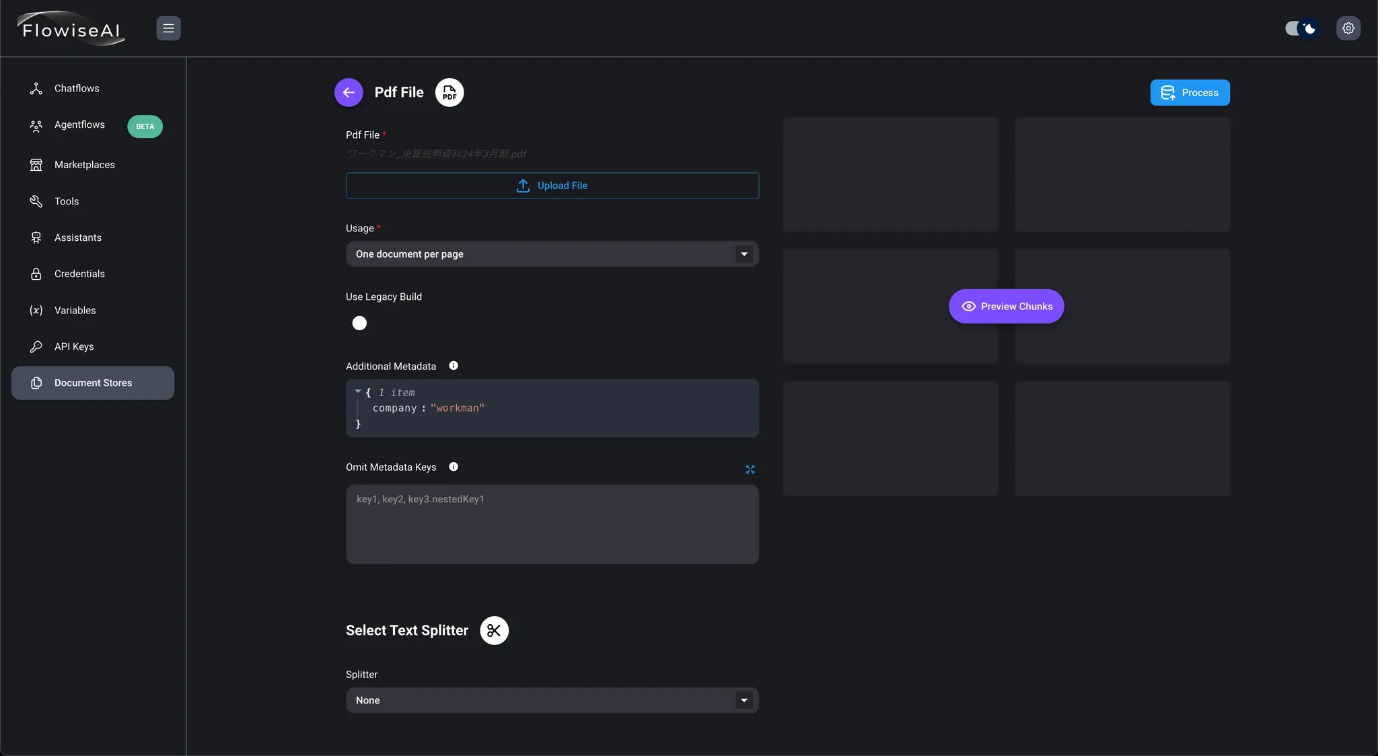
- Seleccione «Un documento por página» en Uso y añada metadatos adicionales.
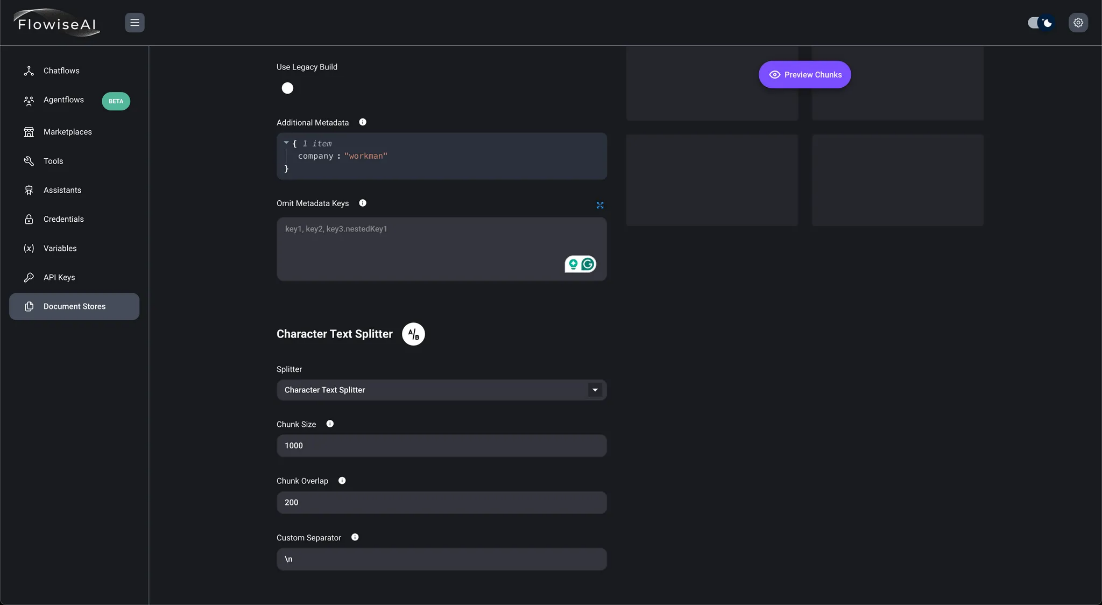
- Seleccione el divisor. Aquí he utilizado el divisor de texto por caracteres.
- Haga clic en el botón «Vista previa de fragmentos» para revisar los resultados esperados.
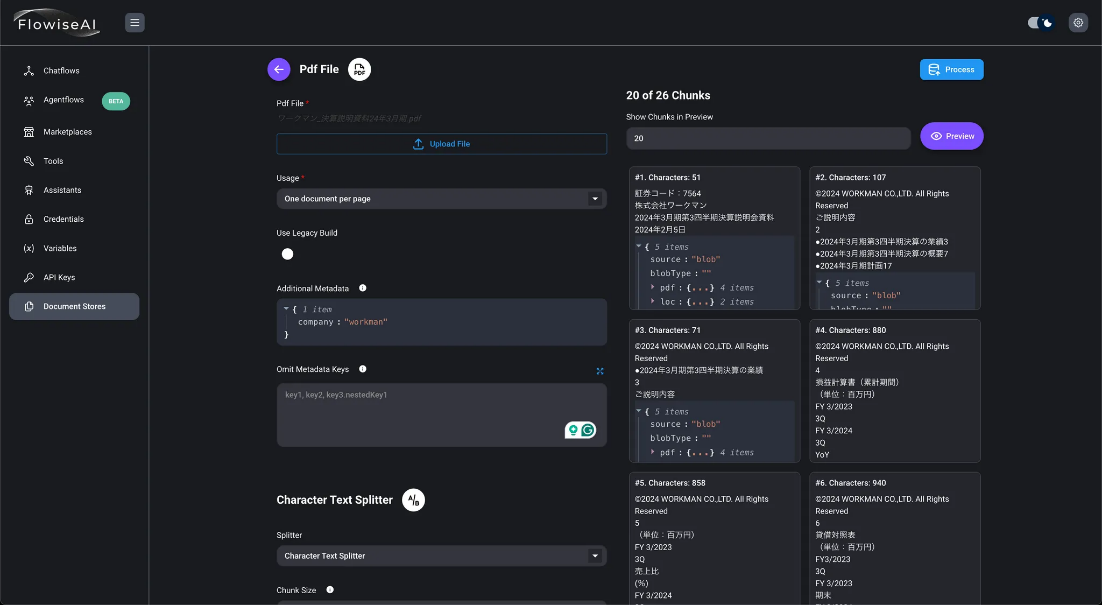
- Después de pulsar el botón «Procesar» para confirmar, volverá a la pantalla superior del Almacén de documentos.
- Úselo de la siguiente manera: